Making mistakes is important for your growth as a developer. I like to say that software development is a continuous series of mistakes and corrections (or problems and solutions, if you prefer to look at it that way). For me, I know I wouldn’t be the awesome developer that I am if I hadn’t already made all the mistakes that I have.
Developers make mistakes; that’s a given because we are human. Making mistakes is a natural part of the development process. The real problem is not that we make mistakes — that’s unavoidable. It’s that sometimes our mistakes make it through to our customers, where at best they’re embarrassing, and at worst they cost the business time and money.
What we need as developers are tools and techniques to help us catch our mistakes before they travel too far. Luckily, we can learn from the mistakes of others, and we have access to a broad range of techniques and practices we can deploy to preemptively mitigate the risk of mistakes as we go into production.
In this post, we’ll go over various techniques that can help. Using a combination of these techniques gives us the latitude to make the mistakes we were always going to make — and that, in turn, gives us room to learn and grow as developers. It also helps us to discover our mistakes early and minimizes the risk of a breaking change going to production.
Individual developer techniques
I’ve broken these techniques into two sections. First, we’ll cover what you can practice by yourself, and then we’ll go over what you can practice with your team. As you’ll see, there are a lot of things you can do on your own to improve your development practice.
Iterative coding with small commits
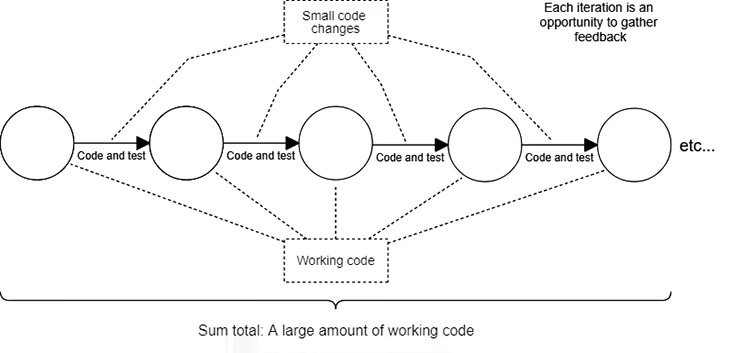
This is something every developer can do. When you write your code iteratively in small increments, you can test and commit each code change independently, making small steps in the direction of your current overall plan. Small changes are easier to test and verify as correct than large changes; they’re also easier to back out of when something goes wrong.
When things do go badly, you can safely reset your working copy. Though you’ll lose your current changes, they won’t be much because you’re only making small commits.
This technique is so important that it’s actually the most fundamental rule in my philosophy of development: when you code in small and simple increments, you keep the code working.
At the end of a day, many small and well-tested code commits will add up to a large amount of new, working code.
Manual code testing
Manually testing your code is a necessary but underrated part of development. Play with your code! Understand what it really does, and not just what you think it does. This is hands-down the best way to pick up mistakes before the code leaves your development computer.
You can test your code in your REPL, from the command line, or using your front-end; you can test your REST APIs using VS Code REST Client, or even create your own testbed if you need to. There are many ways to test — but make sure that you’re really testing your code.
Manual testing is a great starting point for new developers and experienced developers building new products alike. Since there’s significant cost involved in automated testing, it’s generally better to make sure your product is viable before you invest in automated testing. Besides, you need to be good at manual testing before you can be good at automated testing — how could you automate something that you don’t know how to do?
Even after you’ve graduated to automated testing, you’ll still need to fall back on manual testing from time to time. Not to mention that someone on your team will have to do manual testing anyway — if exploratory testing doesn’t get done, you won’t likely be able to find the bugs that developers couldn’t imagine.
Setting up your testing environment
If you don’t already have a fast and efficient setup for testing on your development computer, consider that the first thing you need to fix in your development environment.
You’ll want to have a script or framework that you can startup and have your application running and ready to test in just moments — the quicker the better. The compose command in Docker is great for this, and even better, Compose is now built into Docker!
You’ll also need easy access to realistic data for whatever tests you’re planning to run. You’ll need database fixtures, or sets of test data, for different setups of your application. These sets of test data don’t have to be complicated — a set of JSON files will do the job. Then you’ll need a script for quickly loading the data into your test database.
It’s also very important that you have access to a test environment that is similar to your customer-facing production environment. Your company should provide this to you — and if they don’t, they can’t complain when software errors show up in the actual production environment.
You can also make sure that your development environment is configured to match, or match as closely as possible, the test and production environments. Use Docker for this — it’s a great way to ensure that what works in development also works in production, and also works for your teammates.
Code self-review
Self-review is something every developer should be doing, even if you’re also doing peer review.
Reviewing your own code before you commit is possibly the easiest way to spot mistakes in your code before anyone else does. Self-reviews should be quick — assuming you’re making small commits, it shouldn’t take long to review each one while you’re working.
Use the diff feature of your version control software to check the changes you’ve made. Make sure you understand your code changes and the reason or reasons why you’re making this commit. If you don’t understand them, don’t commit yet. Take some time to think about it.
Try explaining your code to an imaginary friend who’s sitting next to you. Some like to explain their code changes to a rubber duck.

Check your own work first, before you have others check it. You might be surprised at how many bugs you can catch preemptively with consistent self-review.
Practice defensive coding
In anticipation of Murphy’s Law, we should always practice defensive coding. It’s naive to think that our code will work all the time — we should prepare for the worst. Our code will throw unexpected exceptions (usually in production, when we aren’t expecting it), our APIs will be used the wrong way, the inputs to our functions will be garbage. Eventually, anything that can go wrong will have gone wrong.
So, we should assume that things will go wrong and make sure our code handles it gracefully.
How do we figure this out? Through…
Defensive testing
You should actively attack your own code to determine how it responds. Randomly add exceptions to the code and see what happens. Use your APIs the wrong way on purpose. Pass rubbish inputs to your functions. Randomly burn down servers — a.k.a. chaos engineering — to be sure your distributed system is fault-tolerant.
When you know how your own code can fail, you’ll be in a better position to handle such failures.
Automated testing
We’ve already covered how necessary it is to test our code every time we change it. And before each production release, we must test code integrated from the whole development team.
Once you’ve learned how to manually test your code, why spend hours laboriously testing it manually when you can put it on automatic instead? These days, there’s not much code that can’t be made amenable to automated testing. We can use mocking to isolate our code for unit testing, or we can get a real bang for our buck with integration testing or end-to-end (E2E) testing.
Automated testing means that we can rerun our testing process at any time without having to invest our own time.
It’s important to acknowledge that automated testing is a big investment. We need to be sure it’s a worthwhile investment before we get into it, but for medium- to long-term projects, automated testing will likely save you a lot of time and money — not to mention, it’s also probably going to catch some embarrassing bugs that otherwise would have made it to production.
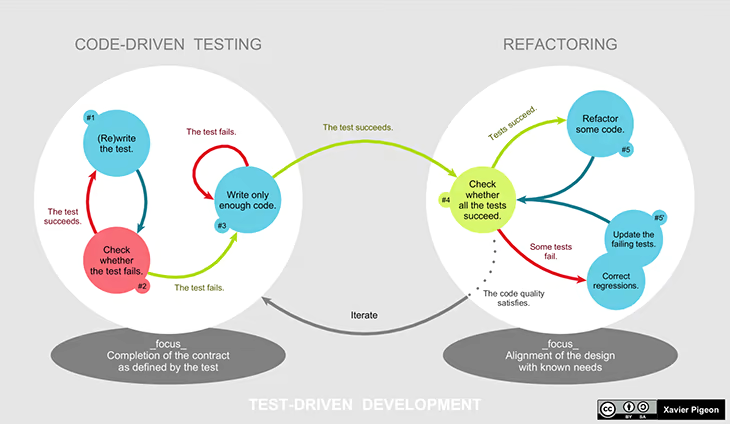
Test-driven development
Test-driven development (TDD) takes automated testing and puts it front and center in the development process: our development is led by the testing process.
TDD achieves an amazing result that you might have to see for yourself to truly believe. The first time you try TDD and you realize that your code works flawlessly after the first run, you will be astounded. It’s rare for code to run correctly the first time — there’s always a problem — but with TDD, it’s perfectly normal for your code to run perfectly the first time, depending, of course, on the thoroughness and reliability of your tests!
Perhaps the most important thing about TDD is that it gets you thinking about testing from the start, which helps you refine your ability to create code that’s amenable to automated testing.
TDD changes you as a developer. The post-TDD developer writes higher quality, well-designed, and better-tested code. Even when a post-TDD developer isn’t doing TDD, their code is going to have fewer mistakes purely by virtue of paying more attention to what they’re writing.
Invest in your skills and development environment
The last thing you can do as an individual developer is to constantly and consistently invest time improving your skills and upgrading your toolset. Always be learning and improving. Always be on the hunt for tools and techniques that can make a difference.
We are privileged to be developers at a time where we have access to a massive and growing ecosystem of tools. We have our choice of programming languages, frameworks, and software and testing tools. You need to understand what’s out there and how it can help you deliver more reliable code — so make sure you’re on top of what’s latest and greatest in the field.
Developer team techniques
Now let’s ramp up to the team level! In the following section, we’ll review a collection of techniques you can practice with your team.
Peer code review
Getting a new set of eyes on your code is a step up from reviewing your own code. Next time you’re about to push code, call your teammate over to look at your code changes. Review the diff change by change. Explain what you’ve changed and why you’re changing it. If you’re working remotely, submit a pull request and have it reviewed virtually before it’s accepted.
This works because your reviewer has a different perspective, and they are likely to spot bugs and deficiencies in your code that you didn’t — or couldn’t — imagine.
Peer code reviews are also a great way to promote communication and share learning experiences across and within the team. It also improves your team’s ability to take criticism — though do take care to ensure you’re serving the well-intentioned kind. Toxic and unconstructive criticism isn’t and shouldn’t be welcome.
Note that this isn’t about blaming you for problems in your code. It’s about getting the team working together to improve the product and find problems that might otherwise make it to production.
Branching strategy
A simple yet robust branching strategy is easy to put in place and can help isolate problematic code. You can also use branches to buffer your customer against problems.
It doesn’t have to be complicated. I like to use the following branches: main, test, and prod. Creating these staging points means that your code has to go through multiple checkpoints before it’s inflicted on your customers.
Developers pushing code to main means that their code is integrated frequently. This helps avoid merge conflicts and ensures that the dev team is working together to integrate their code and fix any problems that occur.
This is the basis for continuous integration, an important practice that predates and underlies continuous delivery. When main is broken, it’s the team’s responsibility to figure out what’s wrong and get it fixed.
Assuming the main branch is healthy when features are ready, main is merged to test. Extensive testing can now be done on test before merging to prod and inflicting the changes on the customer.
Prioritizing defects
Are you working on a codebase that’s already full of bugs and problems? Your focus should be on reducing the defects you already have. A dodgy codebase or a bad development environment causes problems of its own, but it can also decrease developer motivation — which can, in turn, increase the number of problems that make it to production.
Focus first on fixing the worst existing defects before adding new features.
Of course, there’s a balancing act here — we have to keep adding new features to keep the business moving forward — but it’s a trade-off. With the right team structure, we can implement new features at the same time we’re continuously improving the codebase to be more reliable and resilient to failure.
Ensure you have a long-term vision for the health of your product. It can take long hours of persistent and continuous effort to deal with it effectively.
Pair programming
What do you do when you have a tricky problem that’s proving difficult to solve? You ask someone else to sit next to you and help you solve it. Pair programming takes this to the extreme: pairs of developers work together to solve problems side-by-side.
The benefit here is simple: two pairs of eyes spot more problems than one. Pair programming helps developers find problems more quickly and reliably, but it can also greatly improve and expand your experience. There’s really no quicker way to level up as a developer than working in pairs with someone more experienced.
Once you get into a rhythm with pair programming, the bug-free code really flows. It’s like a game of ping pong where the players cooperate to keep the ball in the air for as long as possible.
“Stop the line” with agile development
Agile development traces its roots to lean manufacturing, introduced by Taiichi Ohn of Toyota. In his system, any worker in the factory was able to call a halt to production if they noticed any problems. The problems were then repaired and production restarted. They didn’t tolerate any manufacturing faults.
As developers, we should do the same. Don’t tolerate problems in your continuous integration or continuous delivery systems. If these automated systems fail, the development team must stop working on other projects and focus on fixing them. These are the early warning systems for problems and the checkpoints for code going to production. They are our last line of defense before bugs get to the customer. The team should place the highest priority on keeping these systems working.
But — what happens when problems do get rolled out to production? Should we try and fix them in production? That’s a hard no!
Collect evidence and document the reproduction case as quickly as you can. Then, for the sake of your customer, roll the breaking change back to the previous working version to restore functionality as quickly as possible. Once the pressure is off, you can reproduce and fix the issue in a test environment or development computer, where it can’t bother customers.
Conclusion
Programmers make mistakes and bugs happen. It’s a fact of development, but that doesn’t mean our customers should suffer. There are many ways we can detect — and then fix — problems earlier in our development pipeline.
Since we can reasonably expect problems to occur, we should always be on the lookout for solutions.
Please use the techniques outlined in this blog post to mitigate the risk of errors making it all the way to production. Your development needs will vary, but you have a duty to stop your mistakes from making it all the way to your users.