I've recently made important progress with Data-Forge Plot, so this is a quick blog post to update you on where it's at and where it's going!
First though, a reminder on what this is all about!
What is Data-Forge Plot?
Data-Forge Plot is an add-on library to Data-Forge that adds charting and visualization capabilties. It's also a core technology underlying Data-Forge Notebook, my application for notebook-style exploratory coding, data analysis and visualization in JavaScript.
It's important to note that Data-Forge Plot isn't a new charting library. There's already so many good ones available for JavaScript, I wouldn't want to write a new one and I wouldn't want to have to compete with any of the great options already on the table.
My vision for Data-Forge Plot instead is to have a standard charting API that can be retargeted at any JavaScript visualization library. The advantage to this of course is that you only have to learn a single API and use it to deploy your chart to any supported visualization library.
That's the dream anyway - and with the latest version of Data-Forge Plot we are another step closer to it.
How is it used?
As a further reminder of how it works, let me present some example JavaScript code.
We'll plot a chart from some data that looks like this.
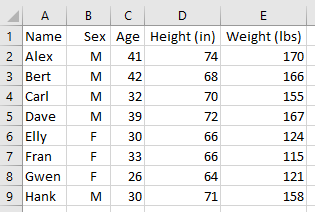 |
|---|
| Figure 1 |
The following snippet of code reads the data file and produces a bar chart:
const dataForge = require("data-forge");
require("data-forge-fs"); // Adds the 'readFile' function to Data-Forge.
require("data-forge-plot"); // Adds the 'plot' function to Data-Forge.
require("@data-forge-plot/render"); // Adds the 'renderImage' function.
// Use Data-Forge to load and parse the CSV File.
const df = await dataForge.readFile("./example.csv")
.parseCSV({ dynamicTyping: true });
// Create a bar chart.
const plot = df.plot({ chartType: "bar", { x: "Name", y: "Height (in)" }));
// Render the chart to a PNG image file.
plot.renderImage("./my-chart.png");The resulting bar chart looks like this:
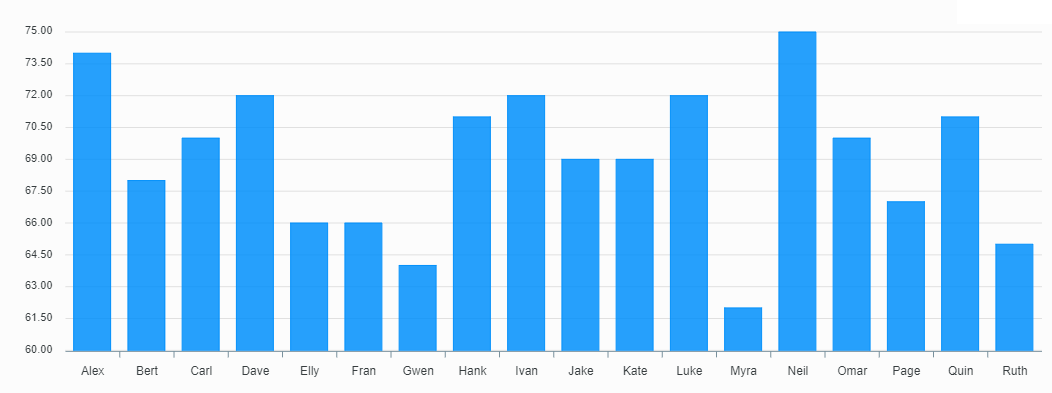 |
|---|
| Figure 2 |
So what's new?
There's been a flurry of activity on this over the past few months, including but not limited to...
renderImage function extracted
The renderImage function (as seen in the code snippet above) has been factored out of the core library and now is an add-on in it's own separate
npm library.
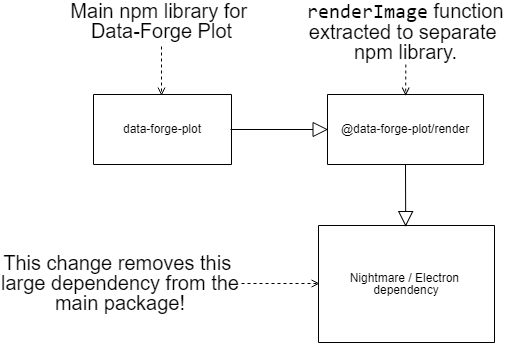 |
|---|
| Figure 3 |
Using the renderImage function now means you must install the additional library @data-forge-plot/render. It's not ideal having to install the extra library, but factoring out this library removes the large Nightmare/Electron dependency from the core Data-Forge Plot library.
This change substanially reduces the Data-Forge Plot bundle size and is a neccessary step to making Data-Forge Plot more generally reusable.
Extracted the chart template
It was always my intention to fully extract the chart templates from Data-Forge Plot and this has finally happened!
Originally Data-Forge Plot only supported the C3 charting library and that was hard-coded, so I started by extracting this to its own npm library. I then created an entirely new chart template for Data-Forge Plot based on ApexCharts.
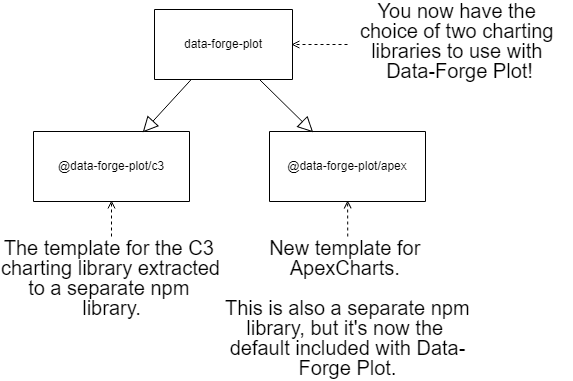 |
|---|
| Figure 4 |
So Data-Forge Plot now supports two JavaScript charting libraries! It defaults to ApexCharts of course, because that's the better charting library - but it also optionally supports C3.
Extracted the chart definition
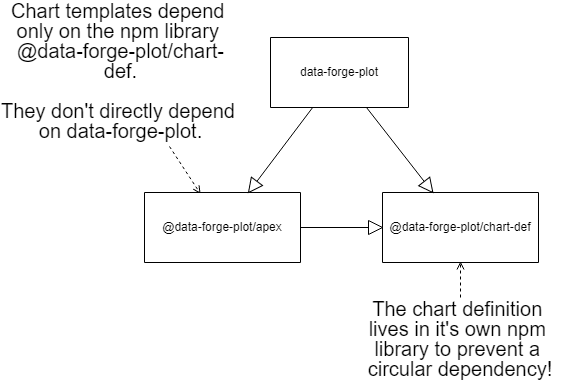
In order to extract the chart templates into separate code libraries I needed to have them and Data-Forge Plot agree on the common structure of a chart. So I factored out another npm library to contain the shared chart definition.
 |
|---|
| Figure 5 |
Another library makes this structure even more complex, but in this case it's necessary to prevent circular dependencies.
All these libraries had to agree on an abstract definition of a chart so that Data-Forge Plot could be made fundamentally independent from any specific JavaScript visualization library and to prevent circular dependencies the chart templates couldn't have a dependency on Data-Forge Plot.
Note in Figure 4 how Data-Forge Plot can reference either of the chart templates, but the reverse dependency doesn't exist. So a separate library was introduced as a home for the chart definition as shown in Figure 5.
The abstract chart definition
So the chart definition was extracted to it's own code library and thus was born the most important concept in Data-Forge Plot: the abstract chart definition.
Why so important?
Well, this turned out to be a pivotal enabling feature for Data-Forge Notebook.
This feature allows charts to be created and saved in an abstract format. The charts can then be targeted against potentially any JavaScript charting libraries: currently ApexCharts and C3 are supported.
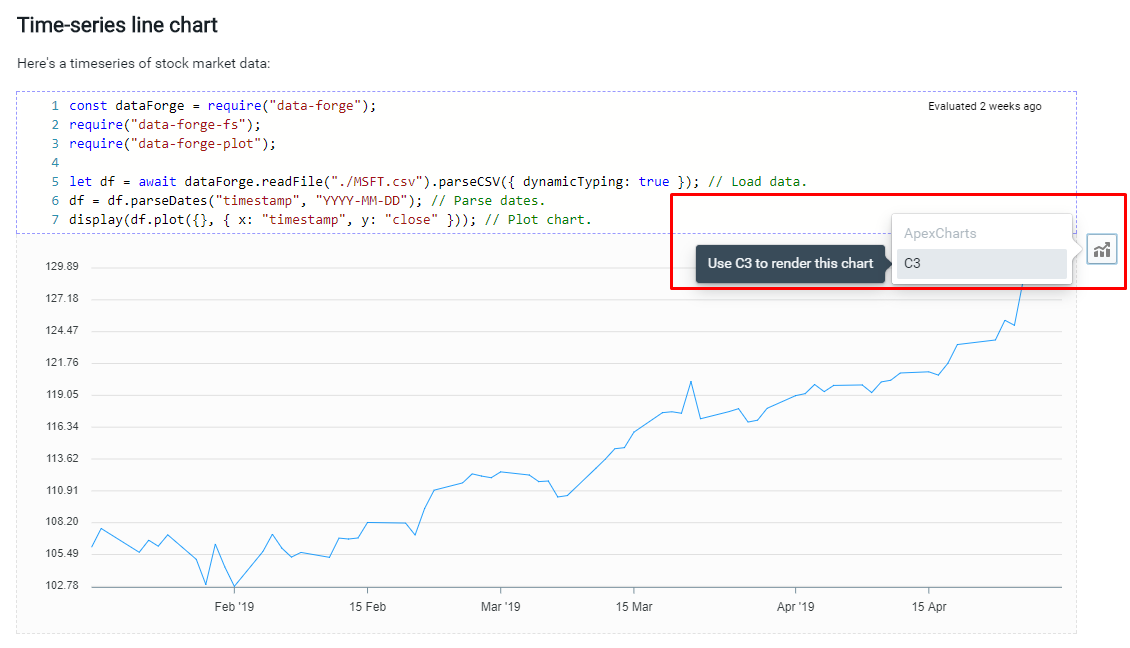
To see what this looks like here's a screenshot of a time-series chart produced in Data-Forge Notebook. Note the button highlighted on the right-hand side that allows the user to choose which charting library is used to render the chart:
 |
|---|
| Figure 6 |
The concept of the abstract chart defintion means that charts can be saved in notebook files and be independent of any specific charting library. This means a user can switch between charts to find a visualization library that best suits their needs. This also allows me as the developer to upgrade Data-Forge Notebook over time to support the latest and greatest JavaScript visualization libraries as they become available into the future.
This is the breakthrough idea that allowed me to move forward in developing Data-Forge Notebook.
The future
My vision of having a single plotting API that can target many JavaScript visualization library is coming to fruition.
Data-Forge Plot can be used standalone in Node.js and it's also a core technology for plotting charts in Data-Forge Notebook.
In the future I plan to support more charting libraries and document the creation of chart templates to hopefully encourage others to contribute templates for their own favourite visualization libraries.
There's another big change coming
Having a plotting library for Data-Forge is very useful and very important. It's great being able to work with dataframes in JavaScript and having Data-Forge Plot makes it super-easy to go from a dataframe to a chart in JavaScript.
But wouldn't it be nice if you didn't even need Data-Forge?
What if you could simply plot a chart directly from a JavaScript data structure or some JSON?
Well that's what I'm doing next. I'm now planning a cut-down version of Data-Forge Plot that is independent of Data-Forge and will be simpler again to use. The name of the new library is currently undecided.
Please stay tuned!