As developers, how do we learn to do difficult things? We start with something simple and progressively scale up to the more complex thing we really want to build.
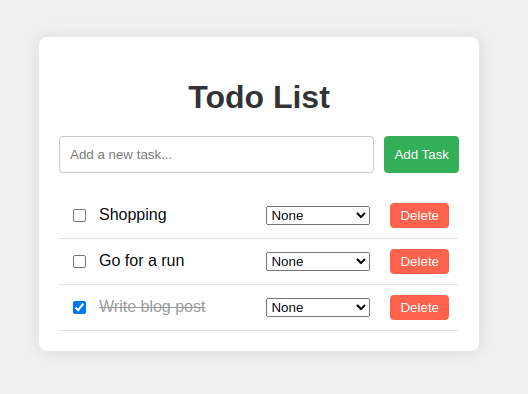
I really wanted to add peer-to-peer data synchronization capabilities to my application Photosphere. But integrating something so complex is daunting. So in the time honored tradition of developers before me, I developed a todo application first to learn and demonstrate the capabilities that I’m interested in.
This todo application runs on different devices and synchronizes changes between them without the need for persistence in the server, a database in the backend, or any kind of cloud storage. The server's job is just to facilitate communication between clients.
This article describes how I stress tested my peer-to-peer todo application to be confident it was never going to go out of sync, regardless of how many devices are sharing data and how frequently. This is probably the hardest thing I ever had to test.
Let’s see how I did it.
Getting the code
The code described in this article is available on GitHub.
Clone the code repository using Git or download the zip file and unpack it.
You’ll need Node.js installed to run the example code. You’ll also need pnpm, which you can install like this:
npm install -g pnpm
Change directory into the project and install dependencies:
cd distributed-todo-app
pnpm install
Try out the front-end
First compile the project so that the shared sync package can be used by the frontend:
pnpm run compile
Now run the broker:
pnpm run broker
Then open up another terminal and start the frontend dev server:
pnpm run frontend
Open two browser tabs and navigate to http://localhost:1234/ in both. You should see two instances of the todo app. Try making changes to either one to see the changes replicated in the other. The front-end instances are communicating with each other via the broker to synchronize their client-side databases.
Try out the test suite
To run the unit tests:
pnpm test
To run the long running randomized test suite:
pnpm run test-runner
The Problem
I want to run my application with minimal back-end maintenance and cost. Minimizing the work in the server means pushing as much work as possible onto the clients. There is not just a cost benefit to this, but it is also better for data safety and privacy. It’s easier to protect our customer’s data when we don’t hold onto it.
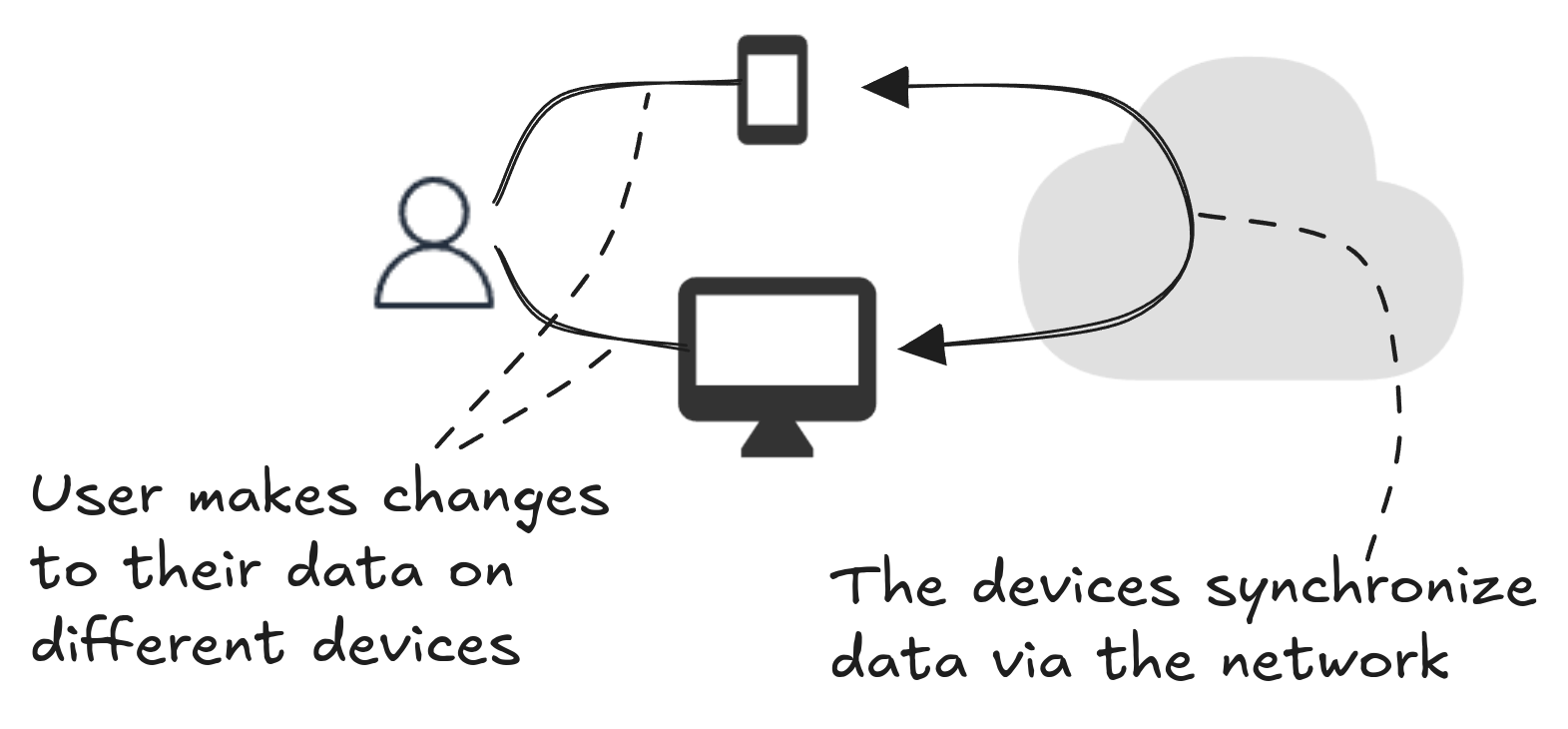
Modern software users expect to see their data on each device that they are using (e.g., mobile phone and laptop computer). Changes they make on one device should be propagated automatically to their other devices. I needed a way to synchronize user data between devices without storing it on the server. So backend databases are out. Cloud storage is out. The devices must talk to each other to exchange data.
The database has to live on the device with the app. When the user makes changes to their data, the client-side database should exchange updates with other clients to synchronize their state.
What’s more, a device can be offline at any time for any duration. So the database on the client must record updates and send those updates out to other clients when it comes back online.
The Solution
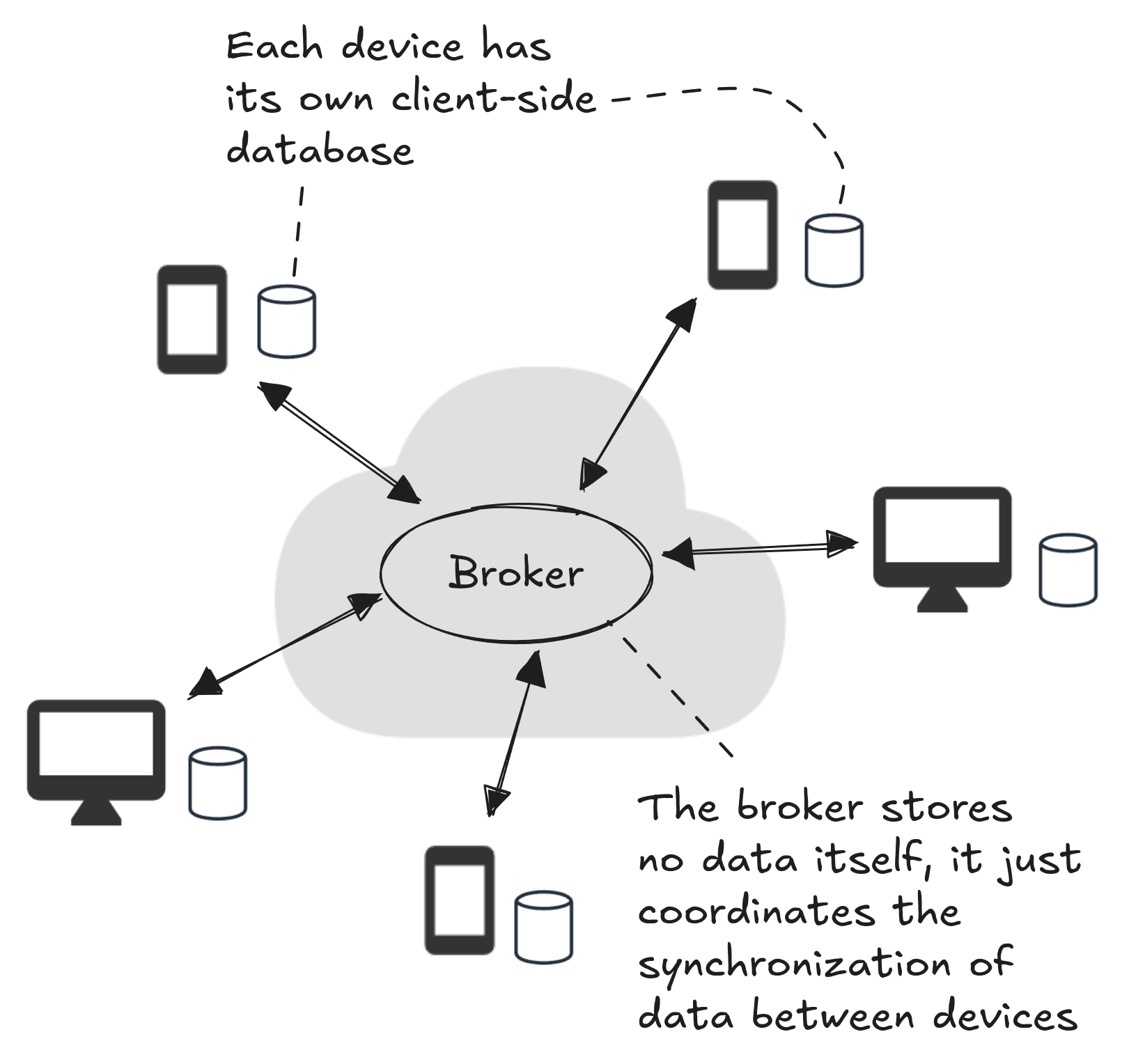
There is no back-end database or cloud storage, but devices need a way to communicate: this will be via the broker. The broker is a minimal server that does nothing but facilitate communication between clients. If the clients were on the same LAN they could communicate directly, but the broker gives them the ability to communicate through the public internet.
As a user makes changes to the todo application on a device, the updates are recorded in the on-device database. When the device is online it advertises those updates to other clients through the broker. As other devices come online they see the advertised updates and request them. The source client then pushes requested updates to the destination clients. In this way, database updates are exchanged between clients via the broker.
Synchronizing State
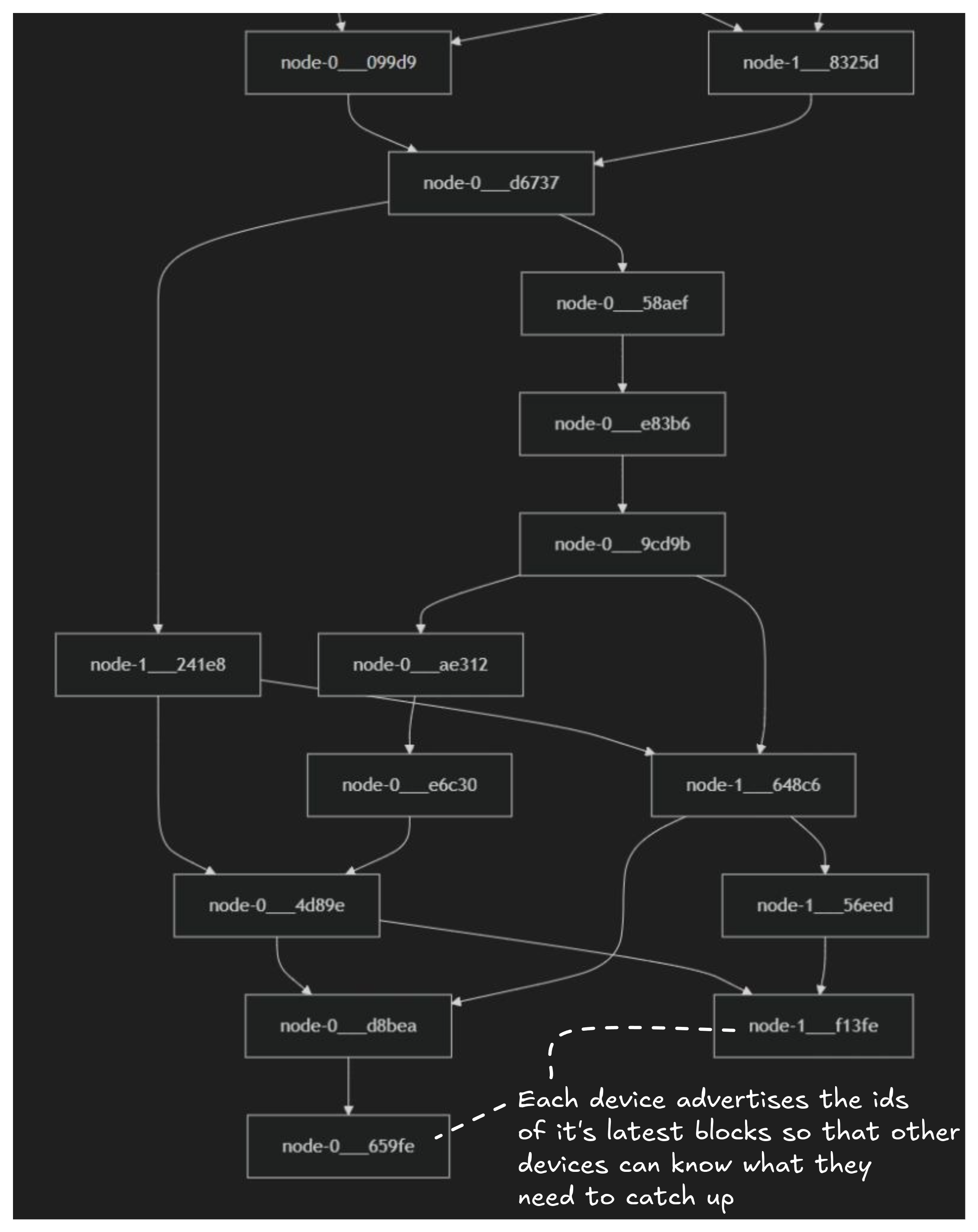
Let’s dive a little deeper into how clients synchronize their on-device databases. As a user makes changes to an app, each individual update is first applied to the local database (stored in-memory for rendering in the app and persisted to indexeddb).
Sets of updates are captured into blocks and each block is assigned a unique ID. New blocks are linked to earlier blocks creating a block graph. At the head of the graph are the latest blocks that have been added by different clients. Each client advertises the IDs of its head blocks to other clients. Other clients therefore can see when they are out of sync and that new blocks are available to be pulled. This is similar to the way Git works.
Replaying Updates
An issue arises when one client pulls updates from other clients. Because the updates were created on separate devices it means that any of them may have been created concurrently. So a naive concatenation of updates from different clients will very likely be in the wrong order.
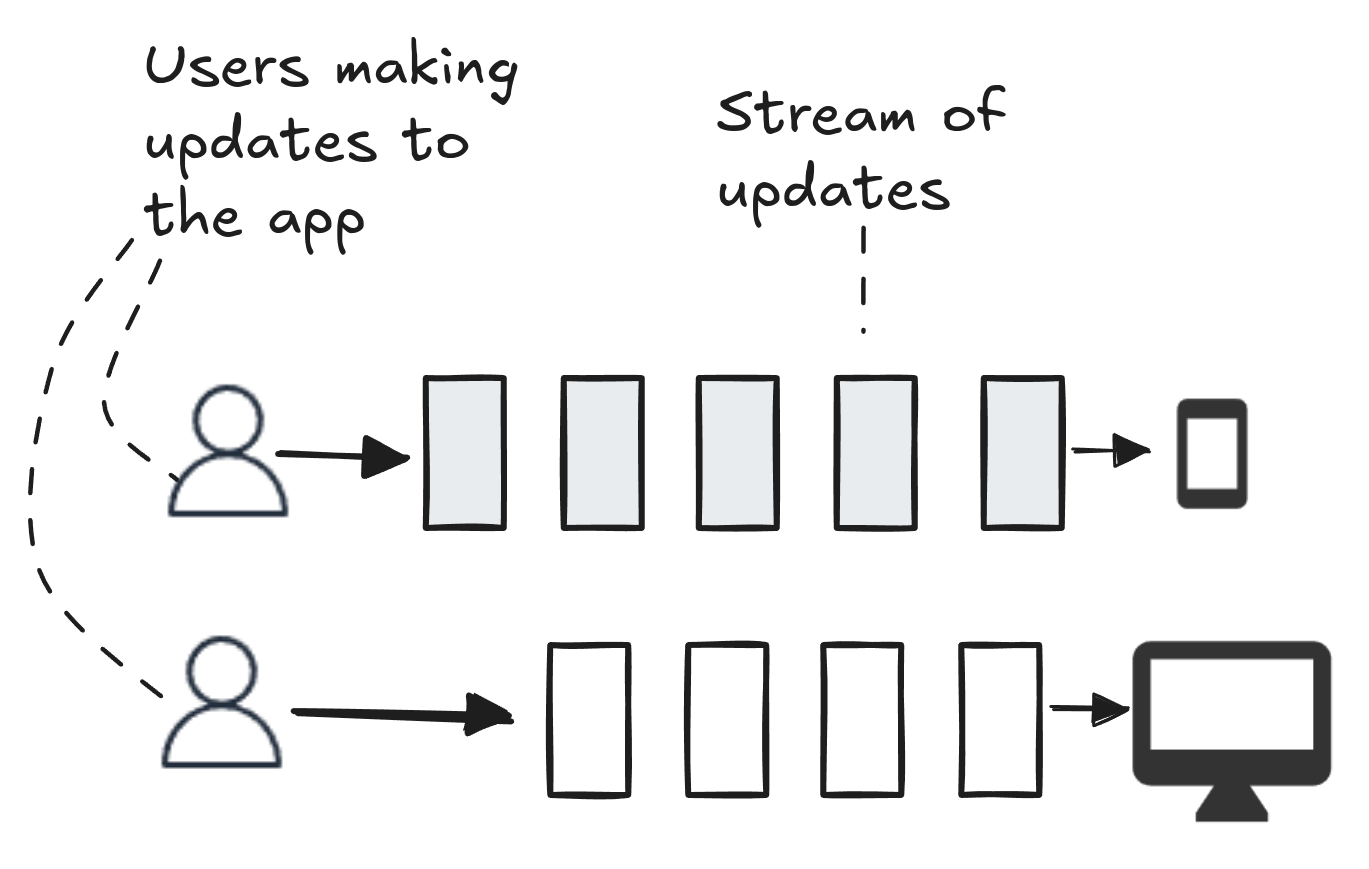
It’s hard to imagine a single user making concurrent changes on separate devices. So instead, imagine multiple users each with their own device but making changes to the same account. Or imagine that one user makes changes on two offline devices (they work on a plane, say). When their devices come back online and the updates synchronize, many updates will be on each device, but they will have to be put in the right order before they are applied to the on-device database.
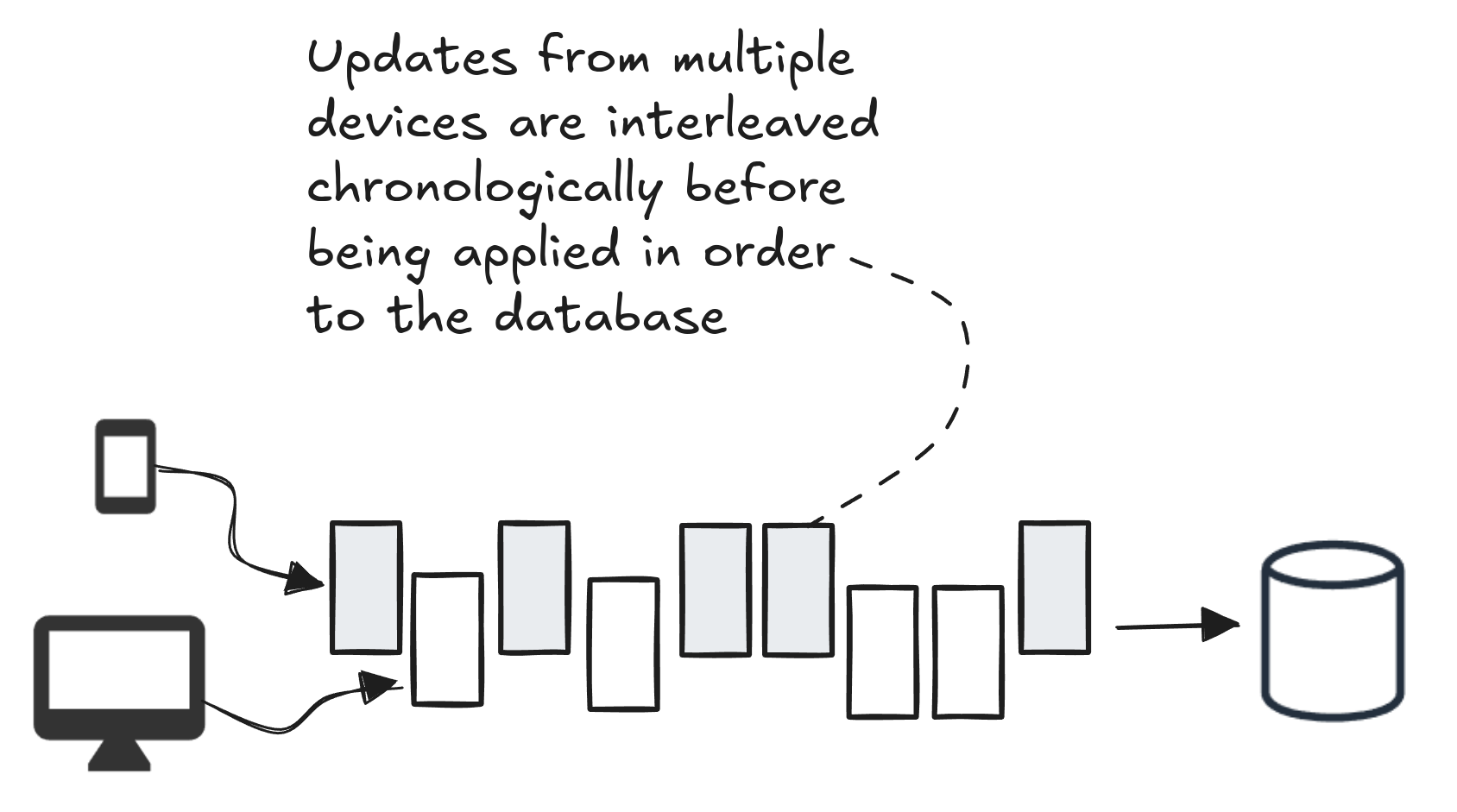
When updates are coming into a client we need to merge those updates and then sort them by timestamp to ensure that multiple concurrent updates are applied to the on-device database in the right order.
But that’s not enough! It is very likely that updates on the current client are made at the same time as updates on other clients, except the current client updates have already been applied to the on-device database. This means that updates applied from other clients may now conflict with updates already made on the current client.
We can fix this problem by replaying updates on the current client that are concurrent with the incoming updates (only just as much as we need to). We merge together all updates from the current client and other clients, sort by timestamp and apply them in order.
Aha, but won’t it cause problems if we replay updates to the database? The solution to this is to make sure every update is idempotent. This means that we structure our code and data in such a way that repeated applications of the same update don’t change the result beyond its initial application. So any update applied more than once has no *extra *effect.
Unit Vs. End-to-end Testing
I started this project with unit tests, but it didn’t really help. Unit tests were actually more of a hindrance early on. The synchronization algorithm evolved repeatedly as I figured out how it should work, requiring constant changes and reworking of the unit tests. At several points, I threw out the code so I could try different algorithms. I also had to throw out my unit tests and all the time that had gone into them.
Unit tests were slowing down my experimentation and stifling my ability to do fast iterations. As soon as it became clear to me that I still had exploration to do, I dropped unit testing.
Without unit tests, I was back to manual testing. But I discovered quickly that manual testing was also not very useful for this project. I started out my testing by running two clients and having them synchronize their data. Manual testing was ok at that point. But once I scaled up my testing above two clients I quickly lost my ability to manage manual testing. What got me up to twenty competing clients was end-to-end testing.
End-to-end testing allowed me to run the system as close as possible to reality. It was the closest possible simulation of many users using the app on different devices. Using end-to-end testing, I was able to find and fix all the problems with my algorithm and ensure that it could handle almost anything.
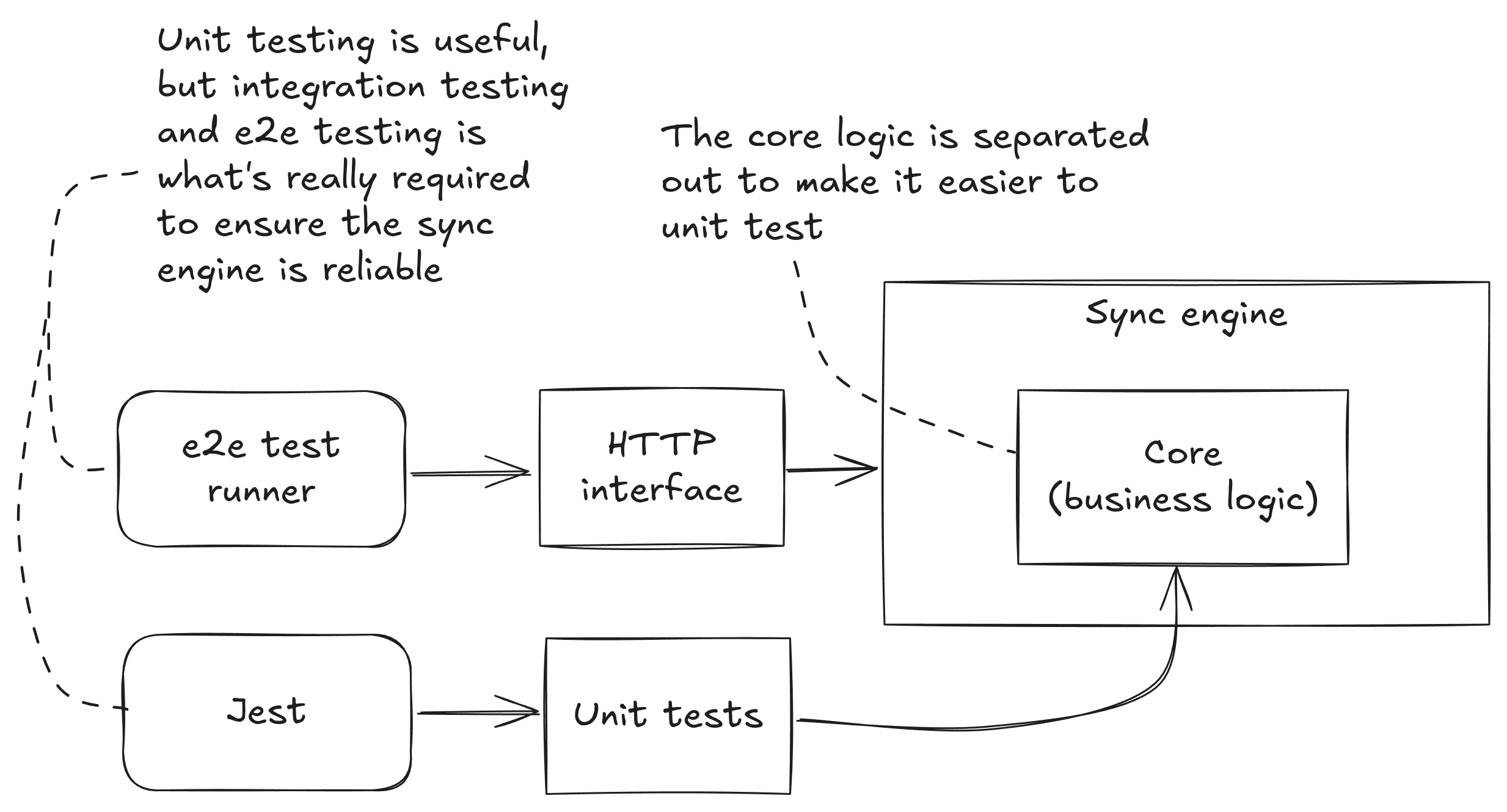
After getting the sync engine working under robust end-to-end testing, I came back and rebuilt my unit tests. Unit tests didn’t work up front in this project, but they still had value at the end to help me iron out any last issues and inconsistencies in the code. Unit tests turned out to be the icing on the testing cake, but not the cake itself.
Because I tried unit testing at the beginning and I knew that I would still want it later, I designed the code to be unit testing friendly. From the beginning, I factored out the core logic (you might think of it as the “business logic”), so that it was separate from the code that dealt with the transport layer (the code making the HTTP requests). This separation would have been completely unnecessary if I wasn’t planning on doing unit tests. It paid off at the end when it eventually made the unit tests easy to rebuild. This separation might also pay off later when I wanted to add different types of transport (e.g., this could be powered by Web Sockets or Server Side Events, as well as HTTP).
See the unit tests for the sync engine.
Making a Custom Node Test Runner
Jest is my favorite test runner and I use it a lot. But early on in this project, I started getting the feeling that Jest wasn’t going to be enough. I was scaling up the number of clients I was testing simultaneously, and then I was scaling up the number of tests I was running in parallel. It was hard to understand what was going on and even harder to debug when things went wrong.
Part way through, I took the plunge and built my own customized test runner. Now I was able to control the output, run tests in parallel the way that I wanted to, and I made it very easy to attach the debugger (VS Code) to the Node.js process when it seemed like it was hung on some infinite loop.
See the code for the custom test runner.

Testing Our Way to Robust Code
Testing an algorithm like this is very difficult because the result is not deterministic.
It’s not because my test cases are making random changes to the database (kind of like fuzz testing). Each test run has specific seeds for the random number generator, so the sequence of random database updates within one client will always be the same.
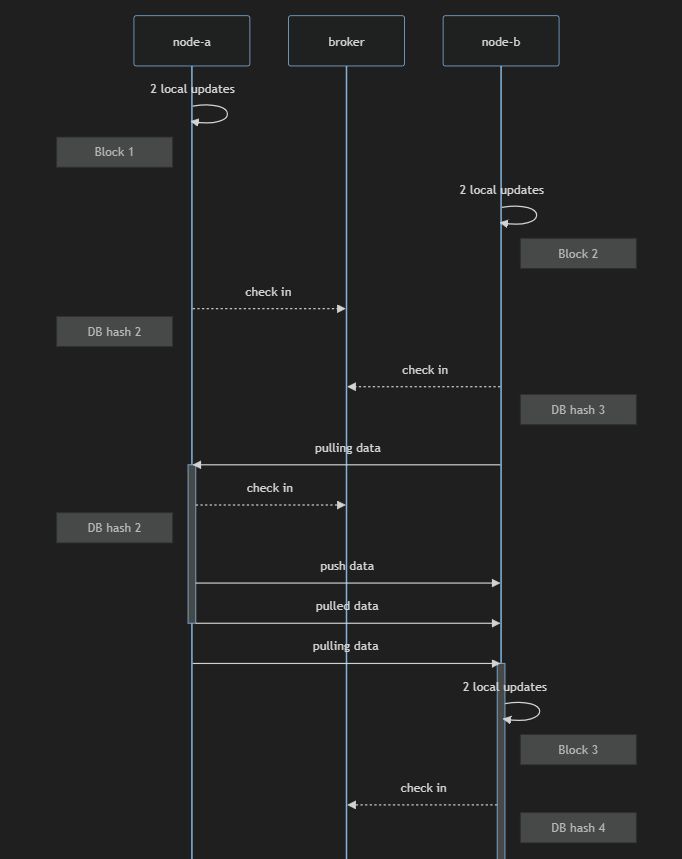
The reason it’s not deterministic is because there are multiple clients running simultaneously and competing to synchronize their database updates. Depending on when the OS schedules each to run (and they might literally be overlapping in real time on separate CPU cores), the sequence of updates synchronized from multiple clients will be in a different order each and every time (even though the stream of updates generated within each client will always be the same).
How does one build such a complex system and have it work flawlessly? The same way we build any code: we have to test it to make sure it works. In this case, the testing has to be more sophisticated. The test runner must wait until the generation phase for each client has finished. It must then give the clients time to synchronize their updates. Finally, it should expect that each client has the exact same state (proved easily using hashes).
See the code that waits for the clients to be synchronized.
The key to success is making sure the tests are easy and (relatively) fast to run. They also must be able to fail reliably and as early as possible. So even though the code we are testing is non-deterministic, the tests themselves must be as rock solid and as repeatable as possible. When synchronization fails, we know there is a problem. We’d like to catch the problem early and repeat it so that we can debug it.
Gear Up for Serious Node.js Debugging
Given the complicated nature of building and testing an algorithm like this, I really got to exercise my debugging skills. You need every trick in the book to pull off something like this!
I used all the usual stuff:
- Console.log to understand what had happened.
- Debugging in VS Code to step through code and see what was happening.
Generating an audit trail (writing files to disk) was also useful to really understand the sequence of synchronizations and the state changes they were causing:
- An event log that captured important events (like integrating incoming blocks or exporting locally generated blocks).
- The sequence of updates applied to the database in each client.
- The state at each tick of the algorithm.
When something went wrong, I had a full and detailed audit trail that I could use to work out how we got into that state. The audit trail was especially useful due to the non-deterministic nature and difficulty in repeating any given test run.
The most useful debugging technique overall was being able to visualize the results. I wrote code to transform the output and audit logs into Mermaid diagrams (the block graph example above and the sequence diagram below). The ability to visualize the behaviour of this algorithm saved me on multiple occasions, where normally difficult-to-see problems seemed to pop right out of the diagrams.
Wrapping Up
I’ve been through extensive testing and serious debugging to implement this complex, non-deterministic synchronization algorithm. My code wouldn’t be working now if I didn’t have automated tests that I repeatedly experimented with and that evolved.
Unit testing is useful, but honestly I could have done without it completely and it wouldn’t have made much difference. It was the end-to-end testing that really was essential to this project.
Do I think that my code is indestructible? Not exactly, but I’ve stress tested my code and I’m very confident that it can perform well under pressure.
This is a good result, considering I’m not even finished testing it. I still have some edge cases to test, like:
- New clients participating later than others.
- Clients going offline and having to catch up later.
- A client frequently going offline (because it has an intermittent connection).
Can my code survive these future test cases? I can’t say for sure: only time will tell. Future stress testing will likely show up new issues. But from this point, I can only get more confident that my code works well in all situations.
That’s the power of automated testing. If a new code change is good, existing tests will continue to pass. If a code change is bad, the tests will fail. I can now see a positive or negative outcome for every code change very directly.
Should you create your own test runner? Probably not. Use Jest or another testing framework in most cases. But it’s comforting to know that it’s not that difficult to create a custom test runner for situations that are complex enough to benefit from it.
Happy testing!